
Immagina un mondo in cui tutte le parole italiane, dai dizionari ai testi antichi, siano collegate tra loro, creando una rete di conoscenza che non solo conserva la lingua, ma ne predice anche l’uso nel futuro…
È proprio questa l’idea alla base di LiITA (Linking Italian), un innovativo progetto dell’Università Cattolica del Sacro Cuore di Milano che mira a costruire una banca della conoscenza linguistica per l'italiano, con l'obiettivo di supportare lo sviluppo di tecnologie avanzate.
LiITA rappresenta un passo importante verso la creazione di risorse interoperabili che connettono dizionari, testi e corpora, favorendo un dialogo tra le parole e le applicazioni tecnologiche più moderne, come l'intelligenza artificiale.
Ma come funziona il progetto? E perché potrebbe rivoluzionare la linguistica italiana? Scopriamolo insieme.
Indice
LiITA: un ponte tra parole e tecnologia
LiITA è un progetto ambizioso che punta a creare una Knowledge Base (KB) interoperabile per le risorse linguistiche italiane. Questo significa che, invece di avere dizionari, testi e risorse isolate, LiITA collega tutto in una rete fluida e dinamica, che permette di tracciare le "occorrenze" delle parole italiane in vari corpora.
In pratica, grazie alla tecnologia dei dati collegati (Linked Data), LiITA rende possibile sapere esattamente dove e come le parole vengono utilizzate, creando una sorta di mappa interattiva del linguaggio italiano.
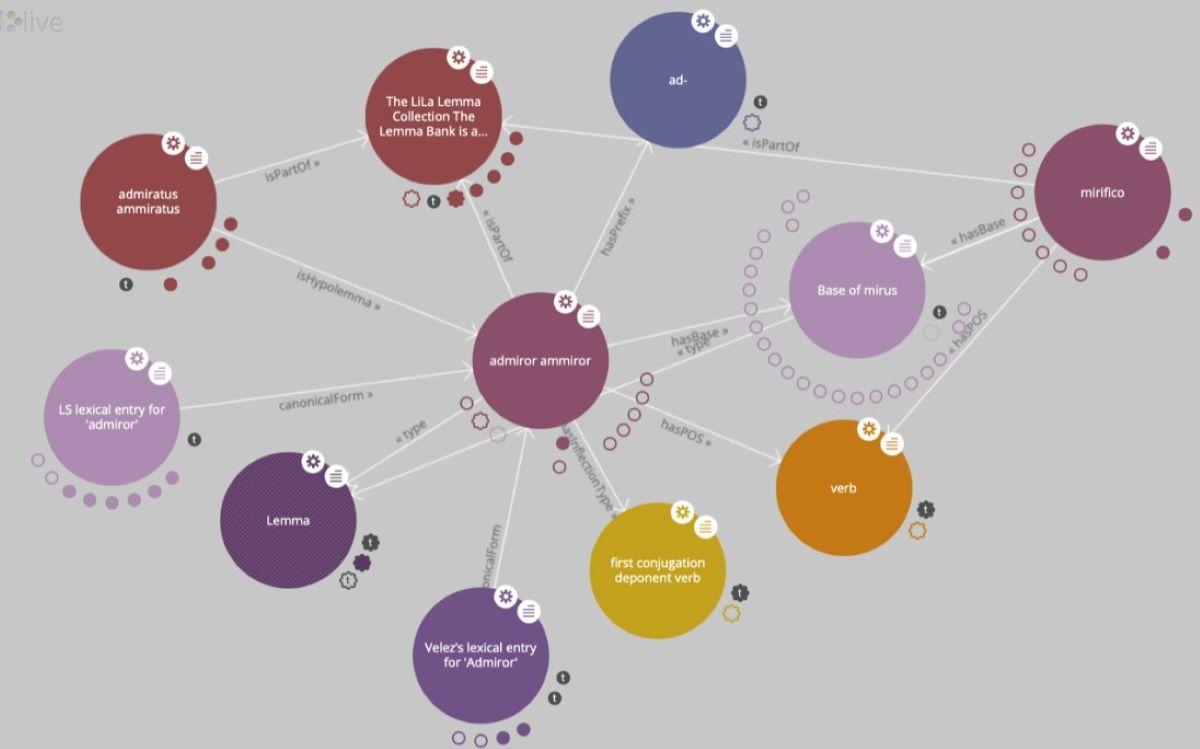
“Il cuore di LiITA è una grande raccolta di lemmi”, spiega il professor Marco Passarotti, coordinatore del progetto. Lemmi che sono le forme canoniche delle parole, quelle che troviamo nei dizionari, e ogni lemma è connesso alle sue occorrenze nei testi e alle voci nei dizionari.
Il risultato? Un “grande grafo di conoscenza fatto di nodi”, in cui sono collegate parole, significati e usi in tempo reale, creando una struttura che può essere utilizzata per raffinare i modelli di intelligenza artificiale.

Una finestra che affaccia sul futuro?
Ecco dove entra in gioco LiITA: la sua Knowledge Base non è solo una collezione di dati, ma una risorsa che può essere sfruttata per perfezionare gli algoritmi di IA, migliorando l'analisi e la comprensione della lingua italiana.
Dunque, LiITA non è solo una risorsa per gli studiosi di linguistica, ma anche per sviluppatori e ricercatori che stanno costruendo applicazioni avanzate per l'analisi linguistica in vari settori, dall’editoria alla medicina, passando per il mondo del web.
La sua capacità di creare connessioni tra dati linguistici diversi aprirà nuove strade per applicazioni intelligenti che comprendano meglio e analizzino la lingua italiana.
Il progetto LiITA sarà presentato alla conferenza "CLiC-it 2024 – Tenth Italian Conference on Computational Linguistics", la decima conferenza italiana sulla linguistica computazionale che si terrà a Pisa dal 4 al 6 dicembre 2024.
LiITA e LiLa: una lunga tradizione di innovazione linguistica
LiITA non è il primo progetto del genere: si basa su LiLa, una precedente iniziativa che ha avuto come obiettivo l’interoperabilità delle risorse per la lingua latina.
LiLa ha raccolto oltre 200mila lemmi e ha sviluppato una struttura unificata per integrare dizionari, corpora e risorse lessicali.

“A ogni lemma”, spiega ancora il professore, “occorrenza di parola nei testi ed entrata lessicale nei dizionari è assegnato un identificatore unico e persistente, consentendo così la loro interazione sulla base di relazioni il cui significato è processabile dalle macchine. L’architettura di LiLa è indipendente dalla lingua e può essere adottata per qualsiasi idioma, tutto è fatto a triple: un soggetto un oggetto e una relazione”.
Ora, con LiITA, l’obiettivo è estendere questo approccio al linguaggio italiano, aprendo nuove possibilità non solo per la linguistica, ma anche per l'innovazione tecnologica.




 Accedi a tutti gli appunti
Accedi a tutti gli appunti
 Tutor AI: studia meglio e in meno tempo
Tutor AI: studia meglio e in meno tempo