Non sorprende che i tentativi fatti dagli enti di standardizzazione, quali il CODASYL a lo ANSI, di sviluppare separatamente il linguaggio di strutturazione dei dati (DDL, Data Definition Language) e quello di manipolazione degli stessi (DML, Data Management Language) hanno portato a molti fraintendimenti e incompatibilità. L'approccio relazionale tende a considerare tutte le relazioni come operatori logici. Il suo scopo principale è quello di evitare dei loop (stallo circolare del computer), un requisito fondamentale per gli utenti finali e un evidente modo per incrementare la produttività di chi scrive programmi applicativi. Edgar F. "Ted" Codd (1923 – 2003), informatico britannico: Relational Database: A Practical Foundation for Productivity (1982)
Edgar Codd scrisse le dodici regole dell'esecuzione analitica online (OLAP: OnLine Analytical Processing) di programmi su data base relazionali. Se ne riassumono alcune tra le più significative:
R1 e R2) Tutte le informazioni comprese in un data base relazionale sono rappresentate in modo univoco mediante un indicatore di riga ed un indicatore di colonna che fa riferimento ad una specifica tabella bidimensionale.
R3) Come in statistica è necessario distinguere i valori NULL (assenza di informazione) dal valore zero (che è un particolare valore numerico). Qualunque campo di un D.B può avere valore NULL.
R4 e R5) Un sistema di gestione di D.B. relazionali deve supportare, per gli utenti finali, un linguaggio d'interrogazione (SQL, Structured Query Language) e per gli specialisti un linguggio per la gestione del sistema (RDBMS, Relational Data Base Management System).
R6 e R7) Per qualunque vista del D.B: debbono essere facilitate le operazioni di aggiornamento (Update), inserimento (Insert) e cancellazione dei dati (Delete).
R8) Indipendenza fisica dei dati: i mutamenti nella struttura fisica di memorizzazione dei dati (vettori, liste indicizzate, ecc.) non devono implicare la necessità di un cambiamento nei programmi applicativi.
R9) Indipendenza logica dei dati: i mutamenti nella struttura logica dei dati (tabelle, colonne, righe, campi chiave, ecc.) non devono implicare la necessità di un cambiamento nei programmi applicativi.
R10) I sistemi volti a garantire la sicurezza e l'integrità dei dati debbono essere generalizzati ed indipendenti dagli specifici programmi applicativi.
R11) L'eventuale distribuzione geografica di parti (o della totalità) del data base su diversi sistemi o reti deve essere invisibile agli utenti finali e ai programmatori.
Quando iniziai a lavorare a metà degli anni 70 si usavano ancora, per archiviare i dati, i files tradizionali (sequenziali o indicizzati) ed ogni programma gestionale (generalmente scritto in linguaggio COBOL) necessitava in input un nuovo file organizzato secondo le esigenze della specifica applicazione; i dati venivano quindi continuamente duplicati. Con l'introduzione dei Data Base questa esigenza venne a cessare, i dati erano archiviati una sola volta nel D.B. e gli applicativi accedevano direttamente ad essi. Vi poteva essere un unico referente responsabile che amminstrava i dati per tutti (Data Base Administrator). I Data Base erano organizzati in tabelle (vedi figura)
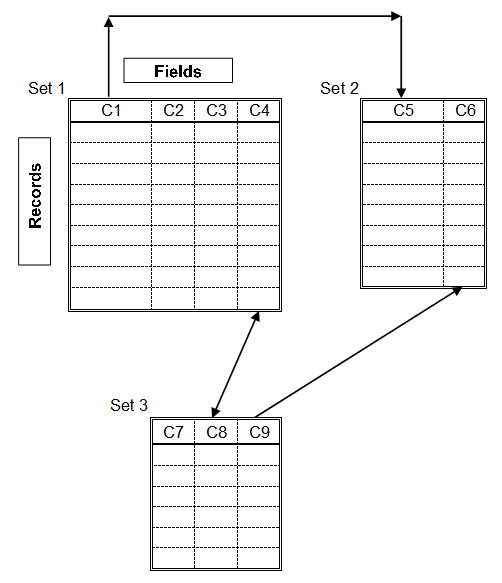
chiamate data set strutturate in righe e colonne. Le ricerche e le selezioni dei dati venivano fatte sulla base di campi chiave che servivano anche come collegamento tra i diversi set. Le due strutture principali per collegare i set di dati erano quella gerarchica (set padri, set figli, ecc.) o quella reticolare (adottata dallo IMS della IBM).
Il nostro gruppo aziendale, che allora disponeva di uno dei più grandi e moderni centri di elaborazione dati in europa, scelse di adottare come DBMS il System 2000, potente, snello e, sebbene gerarchico, con alcune caratteristiche dei sistemi relazionali che ancora non erano sviluppati e diffusi commercialmente. System 2000 era dotato di un linguaggio d'interrogazione (NL Natural Language) e aggiornamento assai semplice che risolveva molti problemi che gli utenti finali avevano nell'interagire con le basi di dati. Si potevano digitare semplici frasi in Inglese del tipo: List C1,C2, C3, C6; Ordered By C1,C7; Where (C3 > 100 AND C1 = Null) OR C2 = "Castoro Sei". Cioè: listami il contenuto dei campi C1,C2,C3,C6; ordinandoli come prima chiave per C1 e come seconda per C7; Selezionami solo i record che abbiano, o C3 > 100 e C1 mancante, o C2 uguale a "Castoro Sei". La società passò negli anni successivi ad ARTEMIS (data base relazionale che disponeva anche di una banca metodi orientata alla gestione dei progetti) e poi a SAP, ma non ho mai più trovato un linguaggio per interagire con il DB semplice, ed orientato all'utente finale, come quello di System 2000.
Codd alla fine degli anni 60, mentre lavorava per l'IBM, creò il modello relazionale per la gestione delle basi di dati, pubblicando "A Relational Model of Data for Large Shared Data Banks" (un modello relazionale di dati per gestire grandi banche dati condivise). Con suo grande disappunto l'IBM, che voleva continuare a commercializzare il suo prodotto reticolare (IMS), tardò a sfruttare le sue idee innovative fino a quando la concorrenza cominciò ad implementarle. Ad esempio, Larry Ellison costruì, sulla base delle idee di Codd, il database Oracle che fu il primo DB commerciale basato sul modello relazionale. La principale forza di questo modello fu e rimase quella di poter stabilire dinamicamente i legami tra i set di dati (purchè avessero un campo comune) al momento della ricerca, senza dover sottostare a strutture rigide progettate a priori come accadeva nei sistemi gerarchici e in quelli a rete.


![Classificare i fenomeni e scegliere le strategie migliori [Pareto]](https://cdn.skuola.net/shared/thumb/159x141/news_foto/images/stories/default_img/pareto.jpg)
![Il foglio elettronico per rappresentare e risolvere problemi [Bob Frankston]](https://cdn.skuola.net/shared/thumb/159x141/news_foto/images/stories/problem_solving/bob.frankston.png)
![Il principio di precauzione e i costi della non scienza [C. Cattaneo]](https://cdn.skuola.net/shared/thumb/159x141/news_foto/images/stories/problem_solving/ogm.jpg)


 Accedi a tutti gli appunti
Accedi a tutti gli appunti
 Tutor AI: studia meglio e in meno tempo
Tutor AI: studia meglio e in meno tempo